04 | 原理:FaaS应用如何才能快速扩缩容?





讲述:蒲松洋
时长16:58大小15.54M
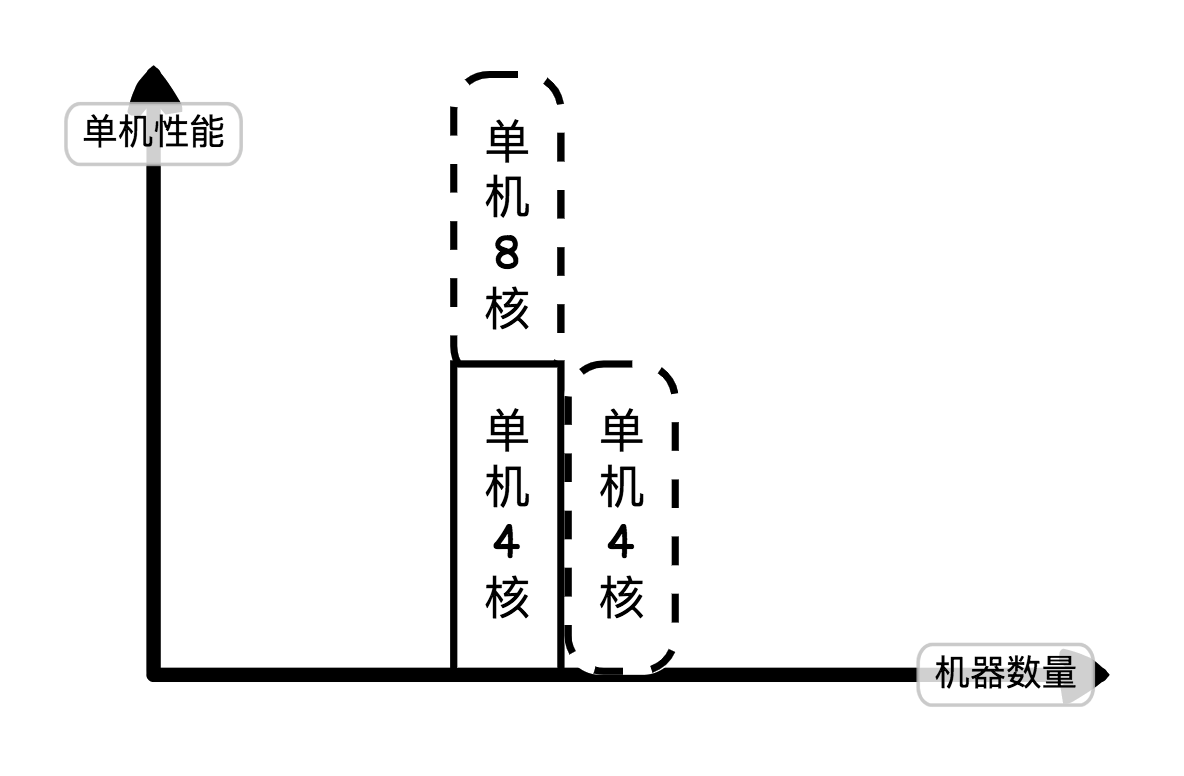
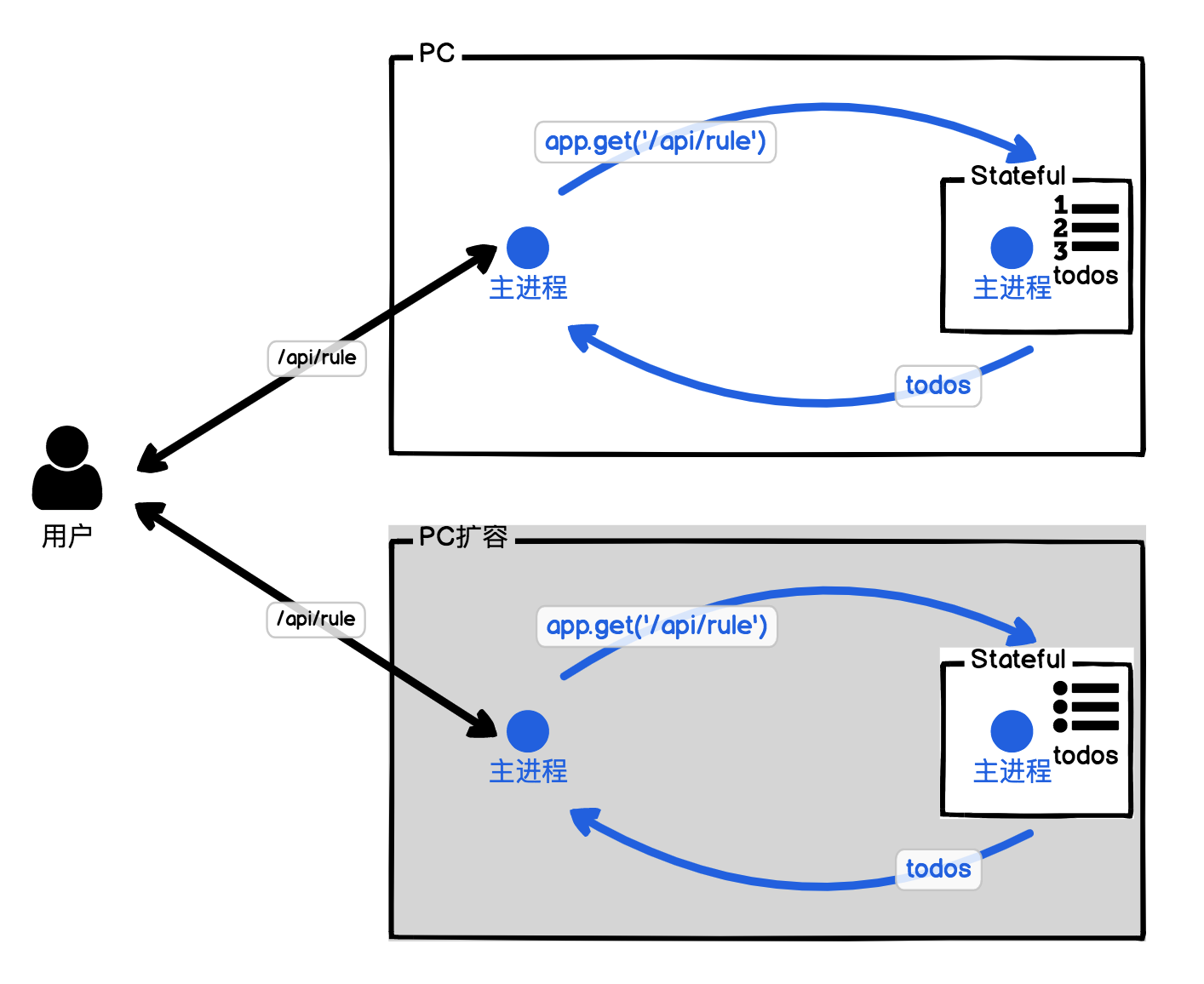
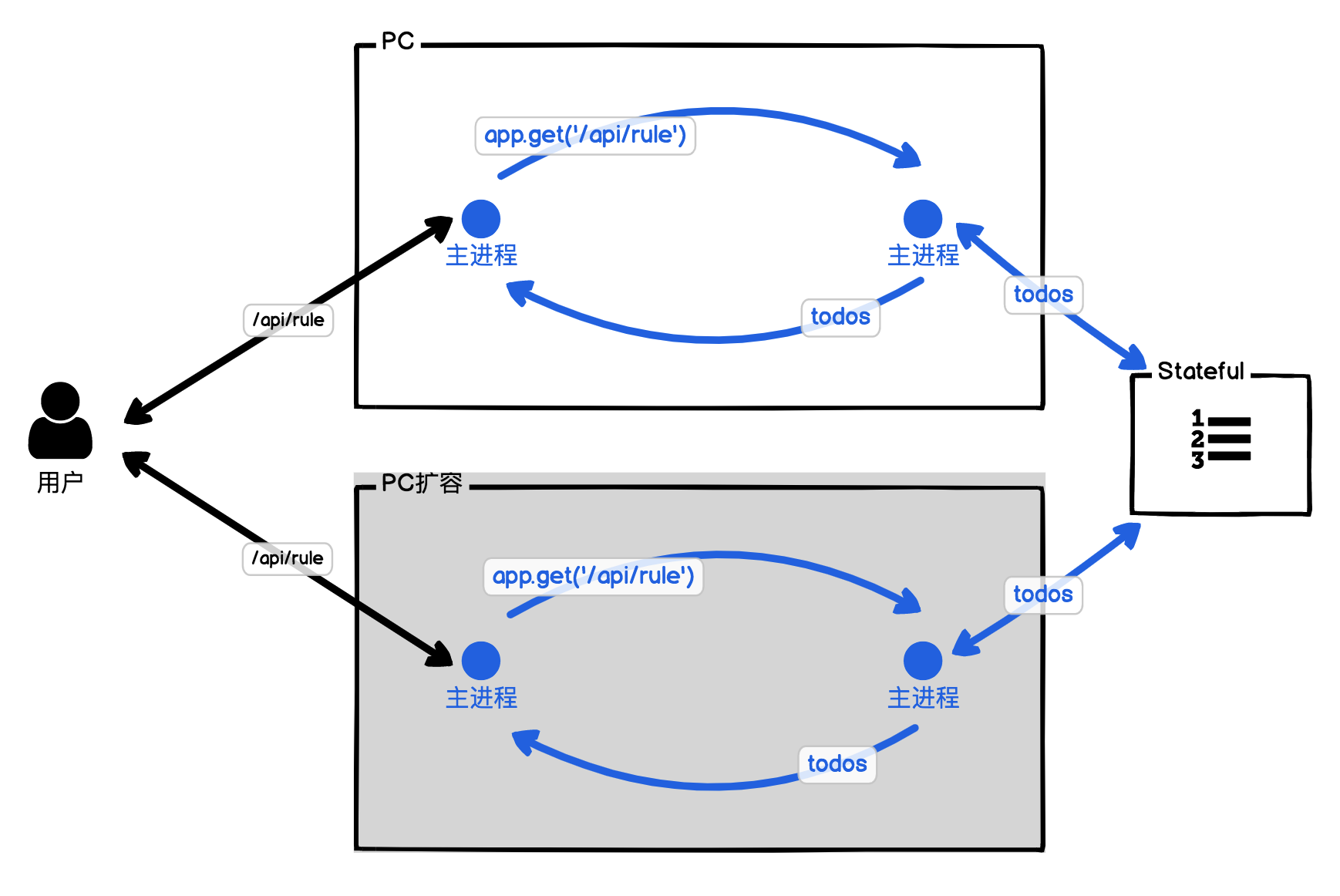
纵向扩缩容与横向扩缩容
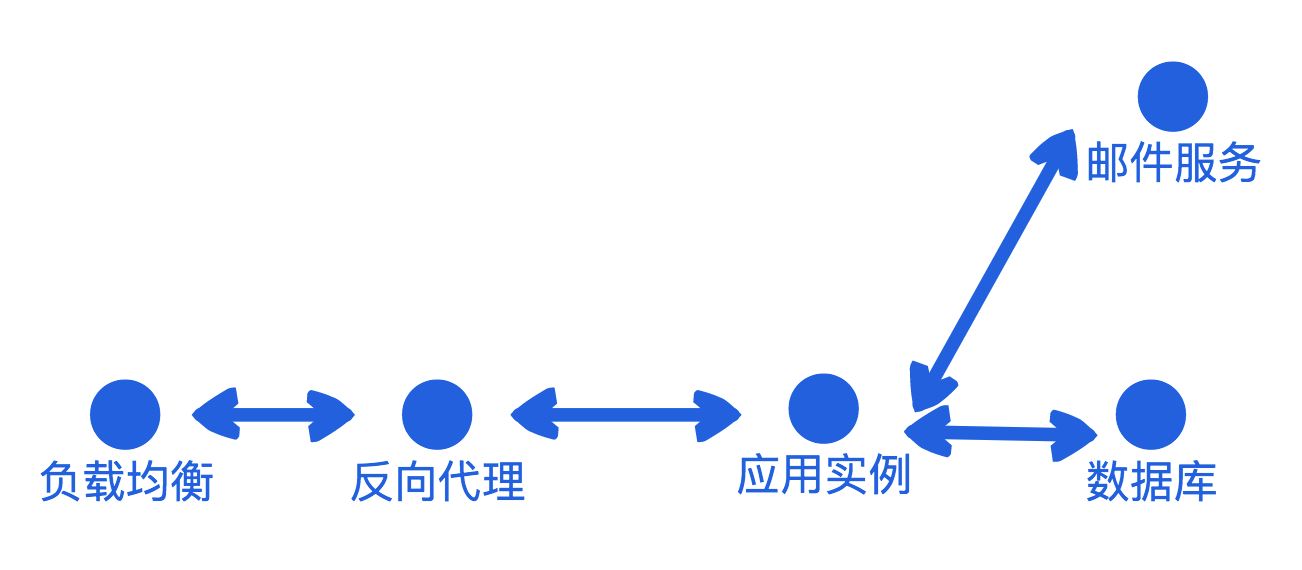
Stateful VS Stateless
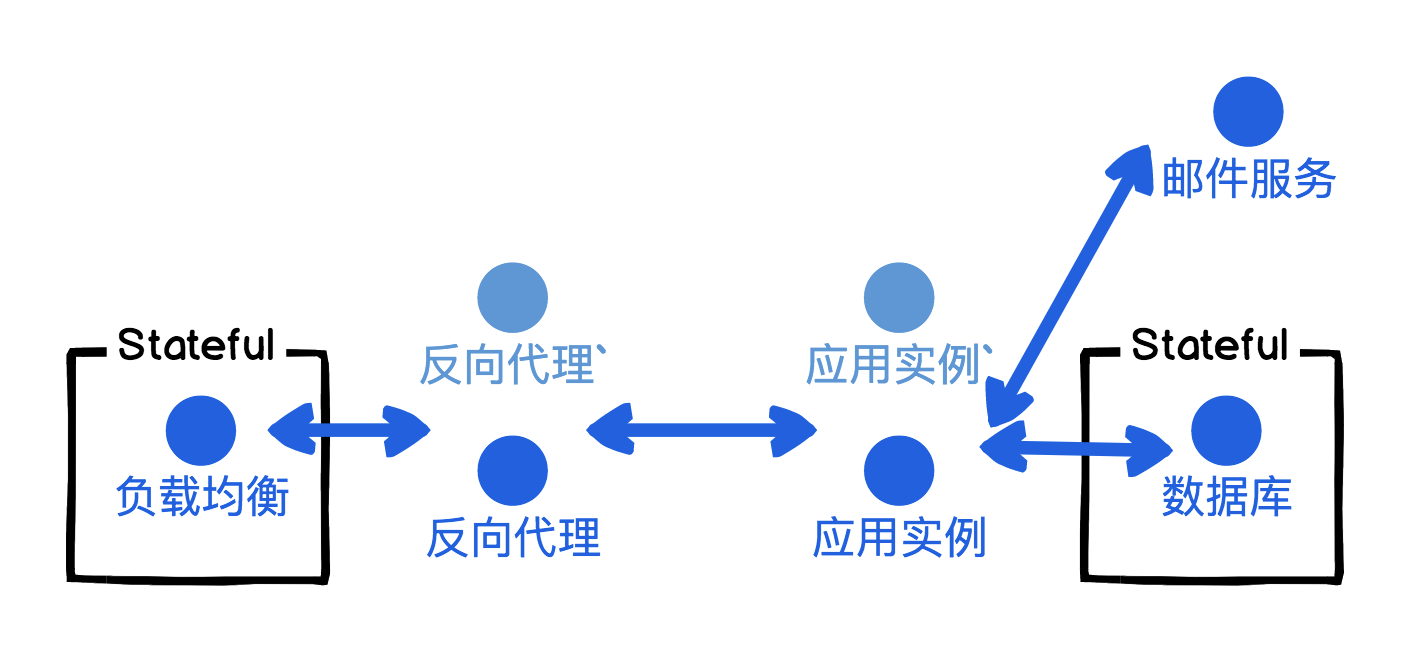
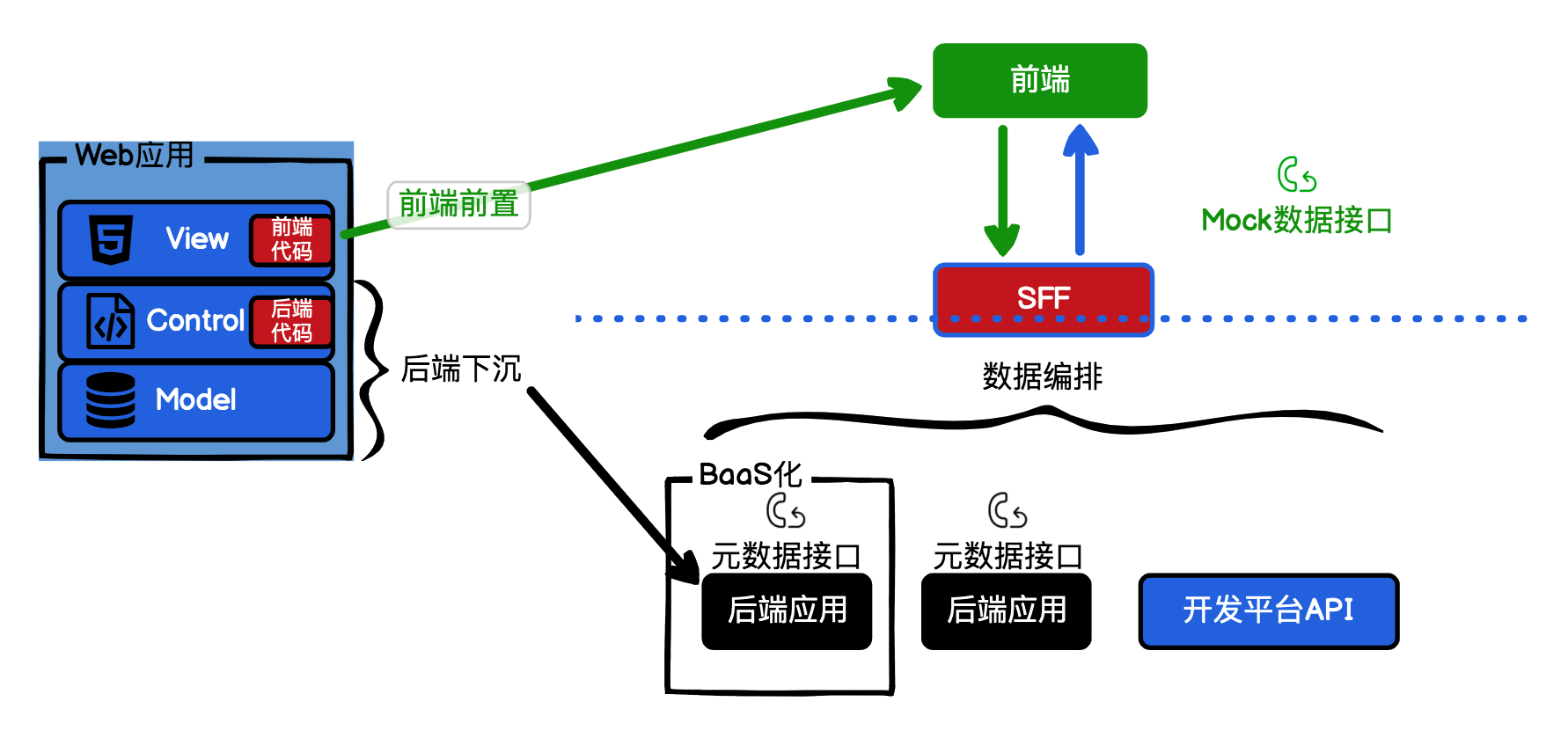
后端应用 BaaS 化
总结
作业
参考资料
1716143665 拼课微信(8)
 蒲松洋 置顶2020-04-24看来很多同学都没有了解过egg.js框架,这里我需要补充一下,我Node.js的主进程和子进程的例子,其实是用了egg.js的进程模型,想跟大家解释这点知识内容。但我代码中的Express.js框架,要使用子进程要额外使用node.js的cluster模块。Node.js是单线程的,但实际它是用event loop让内核的线程去处理事件,响应时再回调handle,其实协程。展开 1
蒲松洋 置顶2020-04-24看来很多同学都没有了解过egg.js框架,这里我需要补充一下,我Node.js的主进程和子进程的例子,其实是用了egg.js的进程模型,想跟大家解释这点知识内容。但我代码中的Express.js框架,要使用子进程要额外使用node.js的cluster模块。Node.js是单线程的,但实际它是用event loop让内核的线程去处理事件,响应时再回调handle,其实协程。展开 1 2020-04-24我比较好奇老师在实践Serverless的过程中踩了多少坑.
2020-04-24我比较好奇老师在实践Serverless的过程中踩了多少坑.
# 我来说说我昨天在阿里云上体验Faas时的采坑记录
## 1. `fun build` 命令无法做到幂等性
相同的输入,经过相同的处理,得到的结果却具有不确定性.
症状是:
借助git命令,保证目录下的文件完全一致,但是执行`fun build`命令的结果却会具有不确定性.
说实话,这个功能对我没任何影响,我只是来体验FC的功能的.他们的基础服务有问题,修不修复对我来说不重要.
但我觉得吧,像这种大厂的用户会比较多,以后难保其他用户不会遇到这种问题.
本着方便后来人的角度,我还是花时间研究了下,如何成功在我本地大概率的复现该问题.
这个问题给他们反馈了,也提供了视频和日志,不确定他们是否会重视这个问题.
## 2. 命令行工具`fun`与VSCode插件行为不太一致
在命令行中使用fun deploy部署时,实际是优先使用的` .fun/build/artifacts/template.yml`文件
而VSCode插件中默认使用的是项目根目录下的`./template.yml`
前者是使用`fun build`命令自动生成的.
我之前其实在命令行中已经照着官方文档把服务部署好了,但是我为了体验VSCode的插件,我又搭建了一次.
这次就遇到了VSCode上部署的服务无法正常工作,提示缺少依赖项.
后来在钉钉群里咨询,才知道现在需要用`fun install`安装依赖.
使用`fun install`安装依赖的方式,再在VSCode上一键部署的服务就是可用的了.
# 最近几天体验函数计算的感悟
## 看上去确实很方便
只要你把服务调通了,几乎不用你操心剩下的运维等工作,现在还有免费额度用,个人肯定是用不完的.
## 排查问题会比较困难
特别是跟服务提供方相关的,对于开发者来说,完全是黑盒操作.
自身代码的调试,还可以借助本地调试功能来排查.
但是一旦提交到了函数计算平台,想查问题就非常难了.
例如:
1. 服务在本地可以正常运行,为什么在远程会提示缺少依赖项?
其实在执行`fun deploy`的过程中,它会帮你把本地目录打包成zip文件,上次到云上,使用zip包内的文件部署函数服务.
而`fun deploy`打包了哪些文件,其实我们是很难知道的.
我上面提到的第二个坑就跟这个有关系.
fun build把依赖包安装到了一个隐藏的目录,与fun install安装的目录并不相同
而fun deploy会根据使用的template.yml文件来确定待压缩文件的路径.
恰巧`fun deploy`又比较`智能`,会优先使用`.fun/build/artifacts/template.yml`,若该文件不存在,才会使用`./template.yml`.
这样,我用fun build安装的依赖文件, 在VSCode上通过一键部署时, 并未打包到zip文件中.
这个也是我自己琢磨出来的.
2. 函数计算的冷启动时间如何优化?
现在连具体的冷启动时间是多长,都无法确定,更无法谈如何优化了.
不清楚 node.js python 的冷启动为什么只有600-800ms, 而用`Custom Runtime`打包的golang服务却要2.5s.
3. 函数的具体单次执行时间如何确定?
目前只能借助云平台的日志,查看函数的平均执行时间.
自己最多只能在函数执行的入口和出口加入时间统计.
我就发现,我用`Custom Runtime`打包的golang服务
显示的函数平均执行时间始终是100ms,而node.js和python的服务耗时时间就是动态的,只有20ms+,远没有到100ms.展开作者回复: 你的回答都很精彩,我都放到部落里了。欢迎你加入微信群一起讨论。
我踩的坑肯定不少,可以在群里讨论一下。掌握了背后Serverless的原理,有助于你定位解决问题。的确目前FC的调试比较困难,所以很多人会去用fun工具。
不过我可以先预告一下,后面的课程,让大家自己用docker容器搭建serverless,可控性更高。就可以本地调试,build/ship/run。最后一课会介绍给大家一个平台,解决调试困难的问题。 1 4- 2020-04-24# 对于 用完即毁型和常驻进程型 的体会
以前我做游戏时,很多状态都是维护在内存中.
这种服务如果迁移到FaaS就很困难.需要做改造,把需要持久化的数据存储到其他地方.
现在做的服务,是基于接口对外提供的服务.
本身不存储状态,都是根据数据库中的数据库反馈结果.
现在的服务,理论上其实可以很方便的迁移到FaaS.
虽然是常驻进程型的,但本身并不存储状态.
就是在初始化阶段,需要连各种数据库,会耽误点时间.
# 对于并发访问的思考
昨天晚上还在想,明天要抽时间用ab压测一下函数计算提供的接口.
看看所谓的`并发度`到底是什么.
之前在文档上看过,一个函数实例可以配置允许的同时并发度,如果不够了,就会冷启动新的实例.
我之前测试的服务都是常驻进程型的,我就想搞个定时任务,每分钟请求一次,保证服务进程不会被回收.
其实每分钟请求一次的消耗也不大,但如果能消除冷启动,绝对是划算的.
但后来一想,这个只针对单实例有效,如果想保证同时有N个实例,如何才能保证定时请求可以将N个实例都访问到呢?
这个需要用再实践一下.
# 课后作业
由于前几天已经配置了阿里云的fun本地环境,自己也有备案了域名,所以实践老师的作业只需要简单的几部.
[我在老师的专栏开始之前完全未接触过node.js 现在也只是跟着老师部署了几个简单的node.js服务]
1. 克隆代码
git clone https://github.com/pusongyang/todolist-backend
2. 拷贝文件
cp index-faas.js index.js
3. 安装依赖
npm install
4. 创建template.yml文件
```
ROSTemplateFormatVersion: '2015-09-01'
Transform: 'Aliyun::Serverless-2018-04-03'
Resources:
todolist-backend:
Type: 'Aliyun::Serverless::Service'
Properties:
Description: 'helloworld'
todolist-backend:
Type: 'Aliyun::Serverless::Function'
Properties:
Handler: index.handler
Runtime: nodejs10
CodeUri: './'
Events:
httpTrigger:
Type: HTTP
Properties:
AuthType: ANONYMOUS
Methods:
- GET
- POST
```
5. 部署服务
fun deploy -y
6. 绑定自定义域名
需要把路径/*都绑定到该服务上
7. 验证效果
可以重现老师的服务: http://todo.jike-serverless.online/list
# 扩展思考
如果只是测试,可以配合NAS服务来持久化部分数据.
我之前写demo时,用这个功能,简单的记录我函数计算服务的访问日志和时间.
仅仅只是测试,并未考虑到多实例并发访问的问题.展开作者回复: 欢迎将你的做法也提MR到github上面来。
https://github.com/pusongyang/todolist-backend/ 1 2  2020-04-24用 fun 部署完成只会,访问 报错啊
2020-04-24用 fun 部署完成只会,访问 报错啊
The CA process either cannot be started or exited:ContainerStartDuration:25516062312, 又没用用 https 咋还有CA证书了?作者回复: 用fun先部署master分支体验一下吧,这节课的分支lesson04-homework,我稍后有时间返回调试一下。
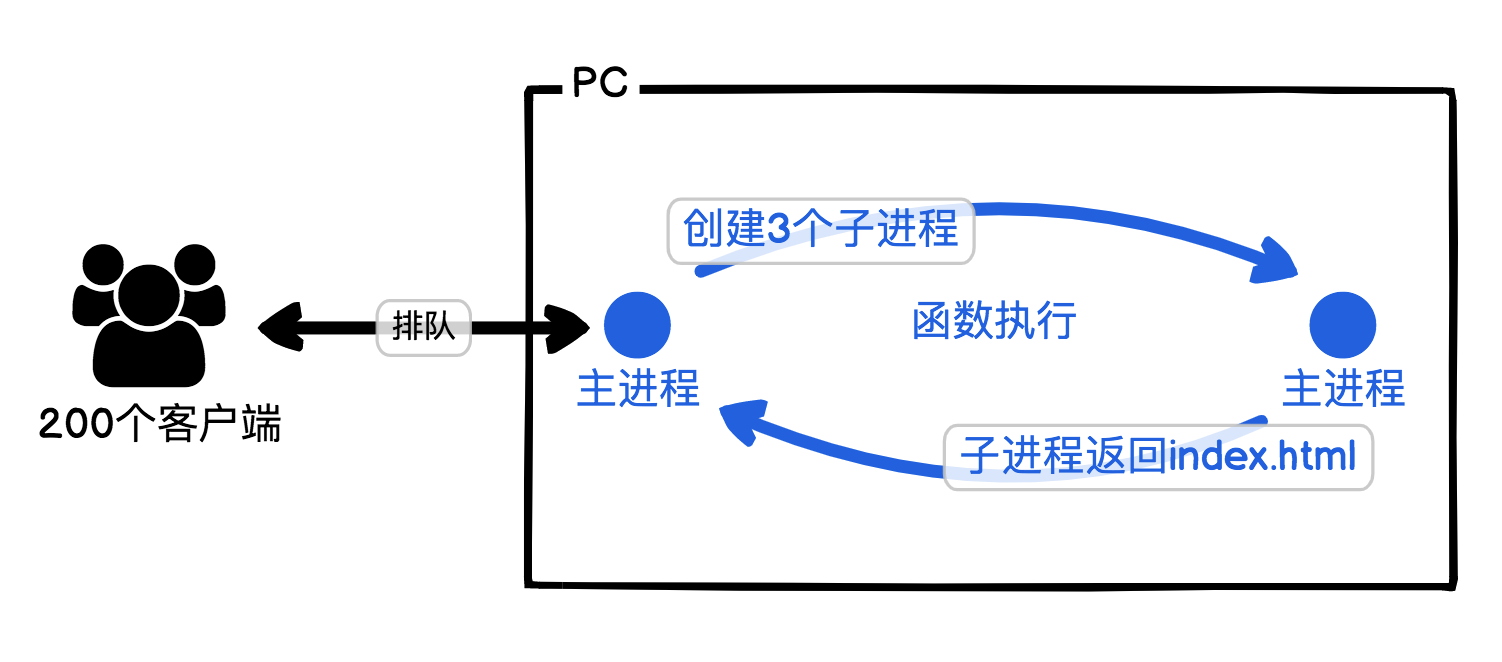
9 1- 2020-04-24当 Nodejs 处理并发请求的并不会自动创建子进程,利多核CPU的的特性。 Nodejs一直都是单线程的
A single instance of Node.js runs in a single thread. To take advantage of multi-core systems, the user will sometimes want to launch a cluster of Node.js processes to handle the load
如果想利用多核 就要使用 cluster 模块
还有就是 并发 是在一个 CPU 核心上交替执行, 在多个 CPU 核心上执行这叫做并行展开作者回复: 这里涉及到Node.js底层的原理:Node.js是单线程的,但实际它是用event loop让内核的线程去处理事件,响应时再回调handle。
为了简化模型,我将它描述为子线程,这里其实协程。
如果自己部署可以VM用PM2启动cluster。或者egg.js框架。 2 1  2020-04-24看了下代码似乎并没有开node多进程...如果是挂在nginx上面的话nginx确实会创建worker进程,但也不是每次请求来都会创建新进程...展开
2020-04-24看了下代码似乎并没有开node多进程...如果是挂在nginx上面的话nginx确实会创建worker进程,但也不是每次请求来都会创建新进程...展开作者回复: 这里涉及到Node.js底层的原理:Node.js是单线程的,但实际它是用event loop让内核的线程去处理事件,响应时再回调handle。
为了简化模型,我将它描述为子线程,这里其实协程。
如果自己部署可以VM用PM2启动cluster。或者egg.js框架。 1 2020-04-24按照这种思路,faas也不需要了,直接前端代码里的js调用baas,一把梭哈,全部搞定。
2020-04-24按照这种思路,faas也不需要了,直接前端代码里的js调用baas,一把梭哈,全部搞定。作者回复: js直接调用BaaS不太安全,不然几年前的mBaaS就应该火了。FaaS可以做BFF层,处理数据编排。还有部分事件触发的场景。毕竟FaaS还是便宜。
1 2020-04-24在传统的服务话架构中,BFF后面的服务是有蛮重的业务逻辑在,BFF本身会做的很薄。在servless中,BASS是否只是对数据层的接口包装?还是也会包含逻辑?谢谢了!
2020-04-24在传统的服务话架构中,BFF后面的服务是有蛮重的业务逻辑在,BFF本身会做的很薄。在servless中,BASS是否只是对数据层的接口包装?还是也会包含逻辑?谢谢了!作者回复: BaaS是后端即服务,将数据库或者一些业务逻辑包裹成API给FaaS编排使用。
但BFF只是FaaS的一个使用场景,有部分BaaS也可以用FaaS去实现的。





